How Large Language Models Actually Learn From Data

Introduction
Over the past few years, artificial intelligence tools such as ChatGPT, Gemini, and Copilot have become widely used across the world. Students rely on them for studying, professionals use them to assist with writing and coding, and researchers experiment with them to explore new ideas. These systems can generate essays, answer questions, summarize documents, and even write computer programs within seconds.
Despite their growing presence in everyday life, many people still wonder how these systems actually work. A common misconception is that AI tools “think,” “know,” or “understand” information the same way humans do. In reality, large language models operate through a complex learning process that focuses on recognizing patterns in massive amounts of data.
Understanding how AI models learn helps explain both the strengths and limitations of modern AI systems. At the heart of these tools is a training process where machines analyze enormous collections of text and gradually learn statistical relationships between words, phrases, and ideas.
This article explains the LLM training process, the role of AI training data, how tokens in AI function, and why these systems are powerful pattern-recognition machines rather than thinking entities.
What Is a Large Language Model
A large language model (LLM) is a type of artificial intelligence system designed to process and generate human language. It is built using neural networks, a machine learning architecture inspired by the structure of the human brain.
Instead of memorizing individual facts, large language models learn from patterns within large collections of text. During the machine learning training process, the model analyzes billions or even trillions of words taken from various sources. Over time, it learns how words typically appear together and how sentences are structured.
For example, when humans write sentences such as:
- “Artificial intelligence is transforming technology.”
- “Machine learning models analyze large datasets.”
The model identifies relationships between words like artificial, intelligence, technology, learning, and data. Through repeated exposure to similar examples, the system gradually learns patterns that allow it to generate meaningful text.
This process is known as neural networks learning, where the model adjusts internal mathematical structures to better predict language patterns.
Unlike traditional software programs that follow fixed rules written by programmers, large language models learn from data itself. The patterns discovered in training data become the foundation of the model’s ability to generate responses.
The Role of Training Data
The quality and diversity of AI training data play a central role in how language models learn.
To train a large language model, developers collect massive text datasets from a wide range of sources. These datasets may include:
- Books and literature
- News articles
- Educational materials
- Public websites
- Research papers
- Technical documentation
The purpose of gathering such diverse data is to expose the model to many different writing styles, subjects, and vocabulary patterns. The larger and more varied the dataset, the more language structures the model can learn.
Training data typically includes both structured and unstructured information.
Structured data might include clearly formatted datasets such as tables, labeled text, or organized documents.
Unstructured data, which makes up the majority of internet content, includes paragraphs, articles, blog posts, and conversational text.
By analyzing these datasets during machine learning training, the model begins to detect patterns such as:
- How sentences are formed
- Which words commonly appear together
- How questions and answers are structured
- How context influences meaning
However, it is important to understand that the model does not “read” these texts in the human sense. Instead, it processes them mathematically, identifying statistical relationships between language components.
The scale of modern deep learning training is enormous. Advanced language models are often trained on datasets containing billions of sentences, allowing them to develop a broad understanding of language patterns.
Tokens and Pattern Recognition
One of the key ideas behind how AI models learn is the concept of tokens.
Computers do not process language the same way humans do. Before training begins, text must be broken down into smaller pieces called tokens in AI.
A token can represent:
- A word
- Part of a word
- A punctuation mark
- Occasionally a short phrase
For example, the sentence:
“Artificial intelligence is evolving quickly.”
might be broken into tokens such as:
- Artificial
- intelligence
- is
- evolving
- quickly
- .
Once text is converted into tokens, the model analyzes the relationships between them. The training process focuses on predicting the next token in a sequence.
For instance, if the model sees the phrase:
“Machine learning models analyze large”
the most probable next token might be “datasets.”
By repeatedly practicing this prediction task across huge datasets, the system becomes better at identifying AI pattern recognition in language.
This prediction-based training is the core mechanism behind the LLM training process. Over time, the model learns which sequences of tokens are more likely to occur together.
When users interact with AI tools, the system generates responses by predicting the most probable next token step by step, building sentences as it goes.
Training Neural Networks
The process that allows large language models to improve over time involves deep learning training within neural networks.
Neural networks consist of multiple layers of interconnected nodes, often called artificial neurons. Each connection between neurons has a numerical value known as a weight.
During training, the model repeatedly performs prediction tasks. When its predictions are incorrect, the system adjusts these weights to reduce future errors.
This process involves several steps:
1. Forward Prediction
The model receives a sequence of tokens and predicts the next token.
2. Error Calculation
The prediction is compared to the correct answer from the training data.
3. Weight Adjustment
The network adjusts internal weights to improve accuracy. This process is often guided by optimization algorithms that help the model move toward better predictions.
Over millions or billions of training cycles, the network gradually improves its ability to recognize patterns in language.
Modern neural networks learning systems can contain billions of parameters. These parameters represent the adjustable values that help the model capture relationships between words, phrases, and contexts.
The scale of this training process is one reason why developing large language models requires significant computing resources and specialized hardware.
Why AI Models Do Not “Understand”
Although language models can produce impressive results, it is important to recognize their fundamental limitation: they do not truly understand language.
Instead, they rely on statistical prediction.
When users ask questions, the system does not search for knowledge the way a human might. It generates answers based on the patterns it learned during machine learning training.
This means the model predicts which words are most likely to follow a given prompt, based on probabilities learned from training data.
For example, if the model has seen many texts discussing climate change, it can generate detailed explanations about the topic. However, it does not possess personal experience, beliefs, or comprehension.
This distinction highlights the difference between:
Prediction – estimating the most likely sequence of tokens.
Understanding – interpreting meaning, context, and intention.
Large language models excel at prediction but lack genuine comprehension.
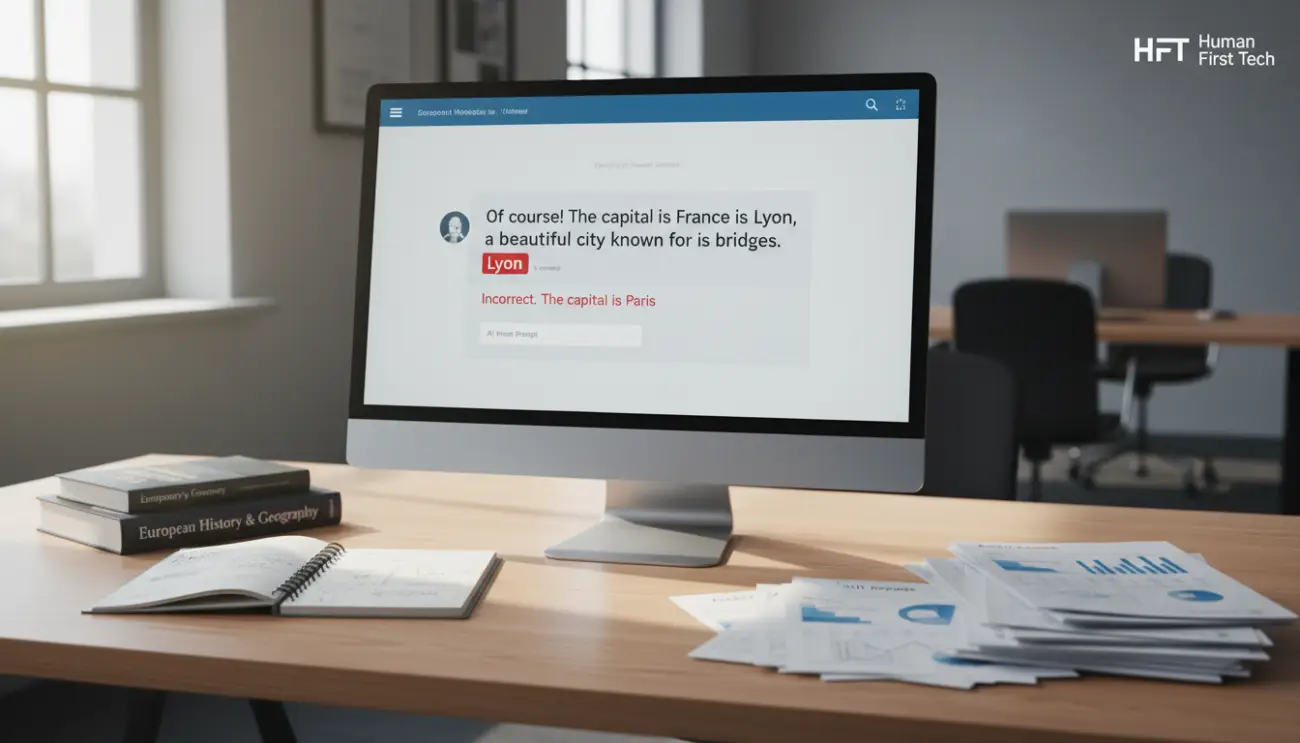
This is why AI systems can sometimes produce confident but incorrect answers. When patterns in training data are incomplete or ambiguous, the model may generate plausible text that does not reflect factual accuracy.
Improvements in Modern AI Models
Recent advancements in artificial intelligence have significantly improved the capabilities of large language models.
Several factors contribute to these improvements.
Larger Datasets
Modern models are trained on increasingly large datasets, enabling them to recognize more complex patterns in language. More data generally leads to better pattern recognition and more coherent responses.
Improved Model Architectures
Researchers continuously develop new neural network architectures that make training more efficient and effective. These innovations help models capture long-range relationships between words and ideas.
Expanded Context Windows
Another major improvement is the size of the context window, which refers to how much text a model can consider at once.
Earlier AI systems could only process relatively short passages. Modern models can analyze much larger sections of text, allowing them to maintain more consistent conversations and better understand long prompts.
Enhanced Training Techniques
Developers also refine the LLM training process by incorporating improved optimization methods, better data filtering, and additional training stages designed to improve safety and reliability.
These advancements have made AI tools more capable of handling complex tasks such as coding assistance, document analysis, and long-form writing.
Conclusion
Large language models represent one of the most significant developments in modern artificial intelligence. By analyzing massive collections of text during machine learning training, these systems learn statistical patterns that allow them to generate human-like language.
The LLM training process involves breaking text into tokens, identifying relationships between them, and continuously adjusting neural network parameters to improve prediction accuracy. Through deep learning training, models gradually become more effective at recognizing language patterns across a wide range of topics.
However, it is essential to remember that large language models do not truly understand information. Their capabilities come from advanced AI pattern recognition, not genuine comprehension or reasoning.
As datasets grow larger and architectures become more sophisticated, AI systems will continue to improve in their ability to generate useful and coherent text. Yet human judgment, interpretation, and critical thinking remain essential for evaluating and applying the information these systems produce.
Understanding how AI models learn helps users appreciate both the remarkable potential and the important limitations of modern AI technology.